C64 datatool - Commodore 64 Tabellenkalkulation |
| Programm: |  |
|
| Anleitung: |
Falls Sie eine andere Quelle verwenden, überprüfen Sie www.webnet.at/c64/datatool_de.htm in Hinblick auf die neueste Version. Es gibt keine Versionsnummer, aber ein Revisionsdatum.
Update: 15. Dezember 2003
Der C64 ist ein feiner Computer für Berechnungen des alltäglichen Gebrauchs: Einfach einschalten, und ein kleines Basic-Programm schreiben. Sollen aber bequeme Möglichkeiten zum Eingeben und Edieren von Daten vorgesehen werden, erhöht sich der Programmieraufwand erheblich, und das C64-Basic hat dafür nicht viel zu bieten. Aus diesem Grund begann ich Überlegungen zu einem Programm anzustellen, das mit Maschinensprache eine bequeme Datenverwaltung ermöglicht, in Kombination mit frei programmierbarem Basic für die Datenverarbeitung. Existierende Lösungen dieser Art konnte ich nicht finden.
Als Hobbyprogrammierer schreibe ich Programme primär für den Eigenbedarf. Dieses Programm könnte möglicherweise aber auch für andere C64-User von Nutzen sein. Gewiß, davon gibt es nicht mehr viele, und noch weniger werden einen Bedarf an so einem Programm haben. Aber wie auch immer, es ist da, es kostet nichts, und wer eine Verwendung dafür hat, kann es runterladen und benutzen.
C64 Datatool eignet sich für das Eingeben, Edieren und Drucken jeder Art tabellarischer Daten. In der einfachsten Anwendungsmöglichkeit kann man damit Listen mit Texten oder Zahlen speichern. Jede Art von Berechnung (Tabellenkalkulation, Statistik oder Datenumwandlung) kann in Basic programmiert werden. In der fortgeschrittensten Art der Nutzung ist Datatool nur eine besondere Umgebung für eigene Basic-Programme.
Eine Anleitung zum C64-Basic gibt es hier: Anleitungen - homecomputermuseum.de
Fertig, getestet und oft benutzt. Vielen Dank an Tom Butz für seine Verbesserung der englischen Programmtexte! Fehlerberichte, Vorschläge und Anmerkungen jeder Art sind erwünscht, Mail an kottira@webnet.at .
Festgestellter Programmfehler: Wird die Überschrift in der Titel-Zeile mehrzeilig, stimmt beim Scrollen die Darstellung nicht und das Programm kann abstürzen. Ich empfehle, den Text in der Titel-Zeile jedenfalls einzeilig anzulegen.
Auf der Diskette sind 8 Files:
Alle Programmfiles können mit oder ohne Sekundäradresse geladen werden. Der Lader führt einen Autostart durch, wenn er mit Sekundäradresse geladen wird, aber generell gilt: alle Files sind von Basic aus ausführbar und können mit RUN gestartet werden. Das Hauptprogramm "datatool.main" ist mit pucrunch von Pasi Ojala komprimiert, weshalb es nur noch 57 statt ursprünglich 77 Blocks auf Disk einnimmt.
Für den Download sind die Files in einem Diskimage
"datatool.d64" gespeichert und gezippt. Download
![]() datatool.zip oder datatool.d64.gz (ca. 25 kB)
datatool.zip oder datatool.d64.gz (ca. 25 kB)
Wenn Sie die Anleitung ebenfalls speichern möchten: Download
![]() datatool+m.zip (ca. 175 kB). Die Dateien sollten in
einen Ordner extrahiert werden.
datatool+m.zip (ca. 175 kB). Die Dateien sollten in
einen Ordner extrahiert werden.
Das Programm ist weitgehend selbsterklärend. Oben am Bildschirm ist das Hauptmenü; ein Menüpunkt wird entweder mit den Cursortasten und RETURN ausgewählt oder mit den Funktionstasten. Sie gelangen nun in eine tabellenartige Oberfläche. Ein Feld wird mit RETURN betreten; um die Eingabe zu speichern, drücken Sie nochmals RETURN. In nahezu allen Situationen bringt die Taste CTRL eine Hilfeseite auf den Bildschirm, die aktuelle Optionen und Tastenkommandos zeigt. Jede Eingabe kann mit der PFEIL-LINKS-Taste (links oben in der Tastatur) abgebrochen werden. Wenn Sie einen laufenden Prozess unterbrechen wollen, drücken Sie die STOP-Taste. Das unterbricht Basic, Disk-Zugriff, Druck und einige zeitaufwendige Operationen. Wenn Sie einen Programmabsturz vermuten, können Sie die Kombination STOP + RESTORE verwenden. Das führt gewöhnlich zu einem Reset des Programms. Während einiger Operationen, die einen Umbau der Arbeitstabelle bedingen, ist der Reset blockiert, da eine Unterbrechung eine unbrauchbare Datenstruktur hinterlassen würde. Die Blockierung kann man umgehen, indem man RESTORE öfter als dreimal drückt - mit dem Risiko, daß alle Daten verloren gehen.
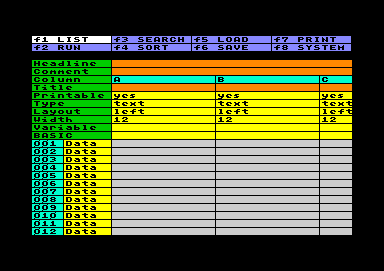 Tabelle bearbeiten
Tabelle bearbeitenIm oberen Teil der Arbeitstabelle sind einige Voreinstellungen zu treffen:
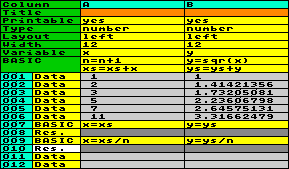
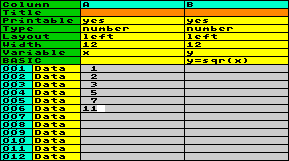 Beispiel: Nehmen
wir an, Sie wollen ein paar numerische Daten in einer Spalte
eingeben und die Quadratwurzel daraus in einer anderen Spalte
berechnen. Nun, zunächst setzen Sie beide Spalten auf
numerischen Typ und geben ihre Daten in Spalte A ein. Dann weisen
Sie der Spalte A eine Variable zu, z.B. x,
und der Spalte B eine andere Variable, z.B.
y. Die Basic-Anweisung lautet
y=sqr(x). Wenn die Arbeitstabelle nun ausgeführt wird
(Hauptmenü f2 RUN), passiert folgendes: Der Inhalt der
Datenfelder in Spalte A wird in die Variable x
übertragen, die Basic-Anweisung wird ausgeführt, und der Inhalt
der Variable y wird in Spalte B
gespeichert. Das wiederholt sich Zeile für Zeile. Danach sieht
die Arbeitstabelle so aus:
Beispiel: Nehmen
wir an, Sie wollen ein paar numerische Daten in einer Spalte
eingeben und die Quadratwurzel daraus in einer anderen Spalte
berechnen. Nun, zunächst setzen Sie beide Spalten auf
numerischen Typ und geben ihre Daten in Spalte A ein. Dann weisen
Sie der Spalte A eine Variable zu, z.B. x,
und der Spalte B eine andere Variable, z.B.
y. Die Basic-Anweisung lautet
y=sqr(x). Wenn die Arbeitstabelle nun ausgeführt wird
(Hauptmenü f2 RUN), passiert folgendes: Der Inhalt der
Datenfelder in Spalte A wird in die Variable x
übertragen, die Basic-Anweisung wird ausgeführt, und der Inhalt
der Variable y wird in Spalte B
gespeichert. Das wiederholt sich Zeile für Zeile. Danach sieht
die Arbeitstabelle so aus:
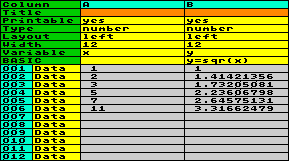
Links in jeder Zeile ist die Zeilennummer angegeben. Sie reicht von 1 bis 999. Aufgrund des beschränkten Speichervolumens können unmöglich alle 26 Spalten und 999 Zeilen mit Daten gefüllt werden, aber z.B. wären (bei reduziertem Basic-Speicher) 3 Spalten mit je 999 numerischen Daten möglich.
Neben der Zeilennummer ist ein Wahlfeld, mit dem der Zeilentyp festgelegt wird.
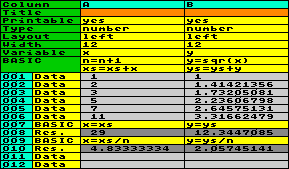
 Beispiel:
in Ergänzung zum vorherigen Beispiel wollen wir die Spaltensumme
und den Durchschnitt von Spalte A und B berechnen. Die Variablen x und y , die
den Spalten zugeordnet sind, können nicht zum Summieren
verwendet werden, da sie für die Aufnahme des Feldinhalts
reserviert sind. Also verwenden wir eigene Variablen für die
Summe, z.B. xs und ys. Und da Basic auch die Anzahl der
Datenzeilen nicht kennt, muß ein Zähler eingerichtet werden;
nehmen wir dafür die Variable n. Das
Addieren der Summe und das Erhöhen des Zählers muß in jeder
Zeile erfolgen, also fügen wir diese Aufgabe dem Basic im
Spaltensetting hinzu, das in jeder Zeile ausgeführt wird. Die
Summen werden nun in eigenen Variablen addiert, aber um diese
sichtbar zu machen, benötigen wir eine Basic-Anweisung, die sie
in die Spaltenvariablen x und y überträgt. Das geschieht in einer
Basic-Zeile am Ende der Datenreihe. Ihr folgt eine Result-Zeile.
Zur Ermittlung des Durchschnitts muß in einem weiteren Schritt
die Summe durch den Inhalt des Zählers n dividiert
werden. Hier ist das Ergebnis nach dem Ausführen der Tabelle:
Beispiel:
in Ergänzung zum vorherigen Beispiel wollen wir die Spaltensumme
und den Durchschnitt von Spalte A und B berechnen. Die Variablen x und y , die
den Spalten zugeordnet sind, können nicht zum Summieren
verwendet werden, da sie für die Aufnahme des Feldinhalts
reserviert sind. Also verwenden wir eigene Variablen für die
Summe, z.B. xs und ys. Und da Basic auch die Anzahl der
Datenzeilen nicht kennt, muß ein Zähler eingerichtet werden;
nehmen wir dafür die Variable n. Das
Addieren der Summe und das Erhöhen des Zählers muß in jeder
Zeile erfolgen, also fügen wir diese Aufgabe dem Basic im
Spaltensetting hinzu, das in jeder Zeile ausgeführt wird. Die
Summen werden nun in eigenen Variablen addiert, aber um diese
sichtbar zu machen, benötigen wir eine Basic-Anweisung, die sie
in die Spaltenvariablen x und y überträgt. Das geschieht in einer
Basic-Zeile am Ende der Datenreihe. Ihr folgt eine Result-Zeile.
Zur Ermittlung des Durchschnitts muß in einem weiteren Schritt
die Summe durch den Inhalt des Zählers n dividiert
werden. Hier ist das Ergebnis nach dem Ausführen der Tabelle:
Beachten Sie zusätzlich bitte auch die Hinweise, die zum Ausführen einer Tabelle gegeben werden.
Beim Bearbeiten gibt es grundsätzlich zwei verschiedene Modi: Wenn Sie eine Tabelle über das Menü betreten, bewegt sich der Cursor von Feld zu Feld, und das jeweilige Feld blinkt. Nennen wir das "Feldmodus". Wenn Sie RETURN drücken, gelangen Sie in das Feld selbst, der Cursor bewegt sich von Zeichen zu Zeichen, und nur das Zeichen in Cursorposition blinkt. Nennen wir das "Eingabemodus".
Das Schreiben und Edieren im Eingabemodus
funktioniert ähnlich wie mit dem C64-Bildschirmeditor, bloß
daß die Wiederholungsfunktion für alle Tasten aktiviert ist.
Zusätzlich gibt es jedoch einen kleinen Zeichenpuffer,
in den jedes Zeichen gelangt, das mit DEL
gelöscht wird. Solange DEL
kontinuierlich gedrückt wird, nimmt der Puffer bis zu 250
Zeichen auf. Um gelöschte Zeichen wieder einzufügen, muß die
Kombination C= DEL gedrückt werden.
Das erlaubt also ein Rückgängig-Machen eines Löschvorgangs.
Kontinuierlich heißt, daß außer der DEL-Taste
keine andere Taste verwendet wird. Beispiel: Sie löschen die
Zeichen "abc", fahren mit dem Cursor an eine andere
Stelle und löschen "xyz". Dann sind "abc"
endgültig verloren, und der Puffer enthält nur "xyz".
Wenn Sie einen Textabschnitt in den Zeichenpuffer übertragen
wollen, ohne den Text selbst zu löschen, benutzen Sie die
Tastenkombination C= HOME. Sie bewegt,
gleich wie die DEL-Taste, den Cursor
rückwärts - Sie müssen also am Ende des Textes anfangen, den
Sie in den Puffer kopieren möchten. Und für den Fall, daß Sie
einen Textabschnitt löschen möchten, ohne den gegenwärtigen
Inhalt des Zeichenpuffers zu überschreiben, können Sie die
Kombination CLR (SHIFT HOME) benutzen,
die sich wie die DEL-Taste verhält,
jedoch nichts in den Puffer verschiebt. INST
(SHIFT DEL) fügt ein Leerzeichen an, was den Puffer nicht
berührt.
Im Feldmodus ist ein anderer Puffer
verfügbar. Er kann Felder, Spalten oder Zeilen aufnehmen. Wenn
Sie ein einzelnes Feld löschen wollen, bewegen Sie den Cursor
dorthin und drücken DEL. Das löscht
den Feldinhalt und verschiebt ihn in den Feldpuffer.
Ähnlich wie oben beschrieben fügt C= DEL
den Pufferinhalt an der gegenwärtigen Cursorposition ein, C= HOME kopiert den Inhalt in den Puffer
ohne das Feld zu löschen, und CLR löscht
den Feldinhalt ohne ihn zu kopieren. Wenn Sie den Cursor in die
Kopffelder von Spalten oder Zeilen bewegen, die den
Großbuchstaben bzw. die Zeilennummer enthalten, können Sie auf
diese Weise ganze Spalten oder Zeilen löschen, kopieren und
einfügen. Beim Löschen mit DEL verschieben
sich die nachfolgenden Spalten bzw. Zeilen. Mit INST können leere Spalten bzw. Zeilen
eingefügt werden.
Bitte beachten Sie, daß DEL im
Feldmodus die Spalte oder Zeile betrifft, in der sich der Cursor
befindet, was etwas unterschiedlich von der Wirkungsweise im
Eingabemodus ist. Und bitte berücksichtigen Sie einige
Einschränkungen, die es bei Feldpuffer-Operationen gibt: Erstens
kann der Puffer nur ein Element aufnehmen, nämlich
entweder ein einzelnes Feld, eine Spalte oder eine Zeile, und man
kann nur dann etwas aus dem Puffer einfügen, wenn das Ziel das
selbe Format wie der Pufferinhalt hat. Beispiel: es ist nicht
möglich, numerische Felder via Feldpuffer in ein Textfeld zu
kopieren. Und wenn Sie eine Spalte von numerischem Typ in eine
Leerspalte kopieren wollen, müssen Sie zuvor die Leerspalte auf
"Number" setzen. Zweitens werden, bedingt durch die
Struktur des Feldpuffers, nur gefüllte Felder übertragen. Auf
diese Weise ist es z.B. möglich, teilweise gefüllte Spalten
oder Zeilen zu vermengen. Falls dieser Effekt unerwünscht ist,
sollten belegte Spalten oder Zeilen mit CLR gelöscht
werden, ehe man sie mit dem Pufferinhalt überschreibt. Und
schließlich ist zu berücksichtigen, daß Pufferoperationen bei
großen Arbeitstabellen einige Rechenzeit beanspruchen können.
Es gibt einige nützliche Tastenkombinationen, nämlich: C= CRSR rechts, C= CRSR unten, and C= RETURN. Bitte entnehmen Sie die Wirkungsweise den Hilfeseiten im Programm selbst, die mit der CTRL-Taste aufgerufen werden. Der Effekt der Tastenkombinationen unterscheidet sich in Eingabe- und Feldmodus.
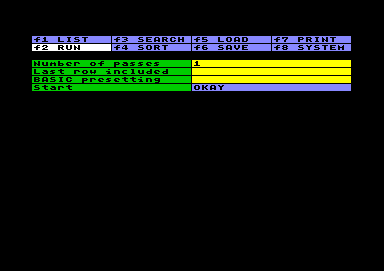 Tabelle ausführen
Tabelle ausführenEine Tabelle ausführen bedeutet, alle Basic-Anweisungen
auszuführen, die in der Arbeitstabelle gespeichert sind. Der
Vorgang entspricht dem RUN in Basic,
bloß daß in diesem Fall Einzelprogramme in strukturierter
Reihenfolge aufgerufen werden.
Zuvor sind ein paar Einstellungen zu treffen:
Wenn Sie RETURN im Okay-Feld betätigen, beginnt die Ausführung der Arbeitstabelle. Das System löscht den Bildschirm und schreibt die Nummer des Durchlaufs oben an. Falls Sie etwas mehr Interaktion während des Laufs wünschen, können Sie entsprechende print-Anweisungen innerhalb der Arbeitstabelle vorsehen. Abgesehen vom begrenzten Zeichensatz unterliegt die Bildschirmausgabe keinen Beschränkungen; sogar ein input von Bildschirm bzw. Tastatur ist möglich.
Um Basic-Anweisungen in der Arbeitstabelle richtig schreiben zu können, kann es wichtig sein zu verstehen, wie das System funktioniert und wie es das Basic umsetzt. Hier in Kürze:
Letztlich ist noch auf einen bemerkenswerten Umstand hinzuweisen, der die Ausführung der Basic-Anweisungen vom Ablauf eines herkömmlichen Basic-Programmes unterscheidet: Es gibt kein übergeordnetes Stop-Kommando. Die Basic-Sequenzen in den verschiedenen Feldern werden abgearbeitet, und wenn eine Sequenz beendet ist, sei es durch end oder stop oder durch das Erreichen der letzten Basic-Zeile, fährt das System mit der Abarbeitung fort, bis die letzte Tabellenzeile im letzten Durchlauf erreicht ist, oder ein Error eintritt. Um von Basic aus die Gesamtprozedur abzubrechen, muß entweder absichtsvoll ein Error in der Art von: if [Bedingung] then crash produziert werden, was den Durchlauf mit einer Fehlermeldung beendet. Oder man setzt den I/O Status ungleich Null, etwa in der Art: if [Bedingung] then poke 144,1 , was den Durchlauf ohne Fehlermeldung beendet. Abgesehen davon gibt es die Möglichkeit, die Ausführung händisch mit der STOP-Taste zu unterbrechen.
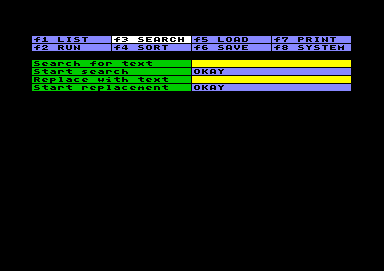 Text suchen
Text suchenDie Suche erfolgt in der Arbeitstabelle, und zwar sowohl in Daten- wie in Settingfeldern, nicht jedoch in anderen Feldern des Hauptmenüs. Beispielsweise ist es möglich, in der Arbeitstabelle nach (Fragmenten) einer Basic-Anweisung zu suchen, nicht aber nach Inhalten, die im Abschnitt " f5 LOAD FILE" vorkommen.
Der Suchauftrag darf eine Länge von maximal 80 Zeichen haben,
ein Überhang wird ohne Fehlermeldung ignoriert. Die Suche
bezieht sich nur auf Textzeichen, es gibt keine spezielle
Suchfunktionen für Zahlen oder Wertebereiche. Natürlich kann
man auch nach Ziffern suchen. Dabei sollte man nicht vom
festgelegten Layout ausgehen, da die Suchroutine den Feldinhalt
so erfaßt, wie er im Eingabemodus angezeigt wird, und dort gibt
es immer nur linksbündige Darstellung ohne Zahlenformatierung.
Ein Jokerzeichen steht nicht zur Verfügung. Sie können also nur
nach exakten Texten bzw. Textteilen suchen. Groß- und
Kleinbuchstaben werden immer unterschieden.
Während der Suche werden gefundene Inhalte am Bildschirm angezeigt, mit CRSR links/rechts können Sie von einer Fundstelle zur nächsten springen. Wenn Sie statt Search die Replace-Funktion gewählt haben, können Sie zusätzlich mit der Taste RETURN den gefundenen Text durch den ersetzen, den Sie in Sie im Feld "Replace with text" eingetragen haben. Ist das Feld leer, wird der gefundene Text gelöscht.
Sie haben jederzeit die Möglichkeit, die Suche zu beenden und im gegenwärtig angezeigten Feld der Arbeitstabelle zu verbleiben, indem Sie die PFEIL-LINKS-Taste drücken.
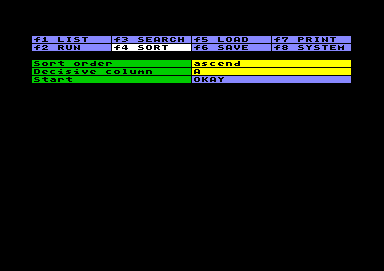 Daten sortieren
Daten sortierenZunächst können Sie auswählen, ob die Daten von niederen zu hohen Werten (ascend) oder umgekehrt von hohen zu niederen Werten (descend) sortiert werden sollen. Dann geben Sie die Spalte an, die für die Sortierung ausschlaggebend sein soll, und betätigen RETURN im Startfeld.
Das System sortiert nur Zeilen vom Data-Typ. Die Position anderer Zeilen (wie BASIC, Result, Label, Pause) wird nicht verändert. Wenn Data-Zeilen von Zeilen anderen Typs unterbrochen sind, sortiert das System blockweise. Völlig leere Data-Zeilen werden nach unten sortiert, egal welche Suchrichtung gewählt wurde. Wenn eine Zeile jedoch belegt ist, wird ein leeres Feld in der ausschlaggebenden Spalte als niedrigster möglicher Wert gezählt.
Wenn Sie hierarchisch in mehreren Ebenen sortieren wollen, müssen Sie die unterste Ebene zuerst sortieren. Das System behält die Reihenfolge der Zeilen bei, sofern die Werte in der jeweils ausschlaggebenden Spalte gleich sind.
Seien Sie gewarnt, daß das Sortieren einer sehr umfangreichen Arbeitstabelle viel Zeit in Anspruch nehmen kann. Der Vorgang kann ohne Gefahr für die Daten mit STOP unterbrochen werden.
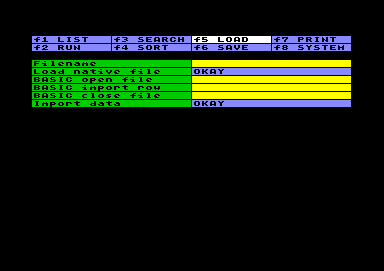 Files laden
Files ladenEine wichtige Einschränkung vorab: Datatool kann nicht auf die Datasette zugreifen, da die Speicherbereiche für den Datasettenbetrieb vom System selbst beansprucht werden.
Es gibt zwei verschiedene Möglichkeiten, Daten von Diskette zu laden. Die erste ist, ein von Datatool selbst erzeugtes File mit Load native file zu laden. Sie müssen nur den Filenamen einzugeben und RETURN im Feld Okay zu drücken. Falls der Filename Leerstellen am Anfang oder am Ende enthält, kann er in Anführungszeichen gesetzt werden. (Wenn Sie den exakten Filenamen vergessen haben, wählen Sie f8, Option "VIEW DIRECTORY" und kopieren den Filenamen über den Puffer.) Das System überprüft das geladene File und gibt eine Fehlermeldung, falls es nicht das richtige Format hat.
Als zweite Möglichkeit können mit der Import data-Option beliebige Daten von Diskette importiert werden. Die Anweisungen dazu müssen in die drei dazu vorgesehenen Basic-Felder eingetragen werden. Das erste Feld wird zum Öffnen des Files ausgeführt, das zweite zum Importieren der Daten, und das dritte zum Schließen des Files. So ähnlich wie beim Ausführen der Tabelle wird die Sequenz zum Öffnen nur einmal durchlaufen, die Sequenz zum Einlesen der Daten aber für jede einzelne Data- oder Result-Zeile von 1 bis 999, bis das Fileende erreicht ist und der I/O Status sich ändert. Dann wird die Sequenz zum Schließen des Files ausgeführt.
| Beispiel: Nehmen wir
an, Sie wollen das Inhaltsverzeichnis Ihrer Spiele-Disks
importieren, um den Inhalt in halbwegs netter Form
auszudrucken, die Files alphabetisch zu sortieren, eine
Datei für gezielte Suche anzulegen, oder so etwas in der
Art.
|
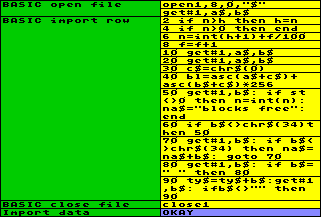 In der
Öffnungssequenz öffnen Sie einen Kanal zum Auslesen des
Directorys "$" von Disk,
und lesen gleich die beiden ersten Bytes ein, die die Ladeadresse
enthalten. Die ist nutzlos und wird nicht weiter verwertet.
In der
Öffnungssequenz öffnen Sie einen Kanal zum Auslesen des
Directorys "$" von Disk,
und lesen gleich die beiden ersten Bytes ein, die die Ladeadresse
enthalten. Die ist nutzlos und wird nicht weiter verwertet.
Die eigentliche Basic-Sequenz, zum Importieren der Zeilendaten,
verwendet goto-Statements und braucht
daher Zeilennummern. Die Zeilen 2 bis 8 kümmern sich um die
richtige Behandlung der bereits in die Arbeitstabelle
eingelesenen Daten. Es ist ja so, daß mehr als nur ein
Inhaltsverzeichnis in die Tabelle eingelesen werden soll, und
folglich beim wiederholten Ausführen der Input-Option bereits
Daten in der Tabelle vorhanden sind. Wenn dies der Fall ist, wird
die Variable n in den bereits
belegten Tabellenzeilen die laufende Nummer enthalten.
Basic-Zeile 2 speichert die bisher höchste vergebene Nummer in
Variable h. Damit ist die Sache in
den belegten Tabellenzeilen auch schon erledigt, und die Sequenz
bricht in Zeile 4 ab, wenn n einen
Wert größer Null aufweist. Anderenfalls kann das Einlesen der
neuen Daten beginnen. In Basic-Zeile 6 wird eine neue laufende
Nummer vergeben, die aus dem ganzzahligen Teil der bisher
höchsten Nummer +1 und im Nachkommateil aus der laufenden
Filenummer /100 besteht. Diese wird in Variable f hochgezählt,
die anfangs Null enthält und in Zeile 8 für jede Zeile des
Inhaltsverzeichnisses um 1 erhöht wird.
Die Basic-Zeilen 10 bis 90 basieren auf dem Beispielprogramm im
Handbuch zur Floppy 1541. Zeile 10 überliest 2 Bytes, Zeile 20
holt die nächsten zwei Bytes, die die Filelänge enthalten.
Zeile 40 errechnet mit der ASC-Funktion
den numerischen Wert, wobei die Variable c$ einen
Error im Falle eines Null-Bytes verhindert. Zeile 50 prüft, ob
das Fileende erreicht ist, reduziert in diesem Fall die laufende
Nummer auf den ganzzahligen Wert, stellt den "blocks
free"-String bereit und beendet die Sequenz. (Um alles
weitere muß man sich nicht kümmern, da durch den geänderten
I/O-Status die Wiederholung der Sequenz automatisch eingestellt
wird.) Zeile 60 wartet auf ein Anführungszeichen, Zeile 70 setzt
den Filenamen in Variable na$ zusammen,
bis das abschließende Anführungszeichen kommt. Zeile 80
überliest Leerzeichen und Zeile 90 sammelt die Zeichen des
Filetyps in Variable ty$.
Diese Basic-Sequenz wird nun wiederholt durchlaufen, und zwar
für jeden Fileeintrag im Directory. Jeder Eintrag wird in Form
der Variablen n,
na$, bl und ty$ in die Arbeitstabelle übertragen und
in einer Tabellenzeile gespeichert. Wenn sich der I/O-Status
ändert, weil das Directory komplett ausgelesen ist, wird die
Basic-Sequenz zum Schließen des Files durchgeführt. Die ist
einfach und besteht nur aus einer close-Anweisung..
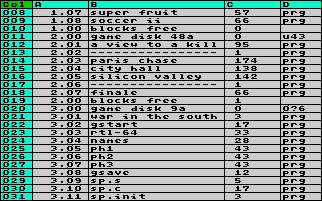 Nach dem Import einiger
Disketten-Inhaltsverzeichnisse sieht die Arbeitstabelle
vielleicht so aus wie der Screenshot links. Sie können
nun die Daten nach Belieben weiter verarbeiten.
(Allerdings wird bei großen Spielesammlungen nach - grob
geschätzt - 50 Disketten Datatool an die Speichergrenzen
stoßen.) Nach dem Import einiger
Disketten-Inhaltsverzeichnisse sieht die Arbeitstabelle
vielleicht so aus wie der Screenshot links. Sie können
nun die Daten nach Belieben weiter verarbeiten.
(Allerdings wird bei großen Spielesammlungen nach - grob
geschätzt - 50 Disketten Datatool an die Speichergrenzen
stoßen.)Dieses Beispiel war etwas aufwendig. Aber es
zeigt die prinzipielle Flexibilität der
Input-Data-Option. Daten können auch von anderen
Programmen, z.B. Textverarbeitungen übernommen werden,
oder man kann selber temporäre Dateien anlegen, um Daten
zwischen verschiedenen Arbeitstabellen zu tauschen, unter
Nutzung der als nächstes beschriebenen Export-Option. |
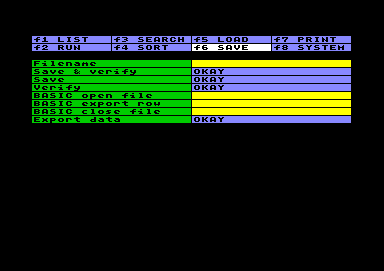 Files sichern
Files sichernAnalog zum Laden gibt es die Möglichkeit, eine Arbeitstabelle
einschließlich aller Settings in allen Menüpunkten als
Datatool-File zu speichern, oder Daten aus der Arbeitstabelle
für weitere Anwendungen zu exportieren. Zum Sichern einer
vollständigen Arbeitstabelle mit Save muß nur
der Filename eingegeben werden (mit Anführungszeichen, falls er
führende oder abschließende Leerzeichen enthält). Gesichert
wird mit einem RETURN im Startfeld der
Wahl: Save, Verify, oder beides. Um ein bestehendes File zu
überschreiben, kann vor dem Filenamen der Zusatz @: verwendet werden. Das System löscht
dann das File auf Diskette vor dem Speichern. (Es verwendet nicht
den fehlerhaften Floppy-Befehl zum Überschreiben.)
Datatool-Files werden als "prg"-File gespeichert und
stellen tatsächlich ausführbare Programme dar. Wenn Sie eine
Session am C64 starten, können Sie ebensogut das File laden und
mit run starten, wie zuerst das
Systemprogramm mit load
"datatool",8,1 laden, und das File danach.
Die Export-Option stellt das Gegenstück zur oben beschriebenen Import-Option dar. Es gibt drei Basic-Felder, um Anweisungen einzutragen. Die Sequenz zum Öffnen des Files wird einmal am Anfang ausgeführt, die Sequenz zum Exportieren der Zeilen wird für jede belegte Data- oder Result-Zeile der Arbeitstabelle durchlaufen (Label-, Pause- oder Basic-Zeilen werden ignoriert), und am Schluß kommt die Sequenz zum Schließen des Files dran. Die Export-Option kann recht nützlich sein, um Daten mit anderen Programmen oder zwischen Arbeitstabellen auszutauschen. Einige Hinweise dazu gibt es im Kapitel Tips & Tricks.
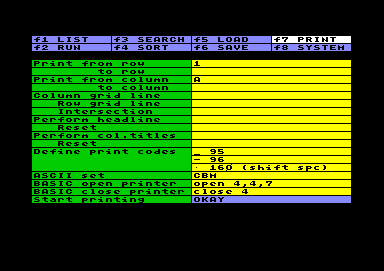 Tabelle drucken
Tabelle druckenDas System bietet keine Treiber für verschiedenen Drucker an,
hat aber trotzdem einige Optionen zur Kontrolle der Druckausgabe.
Die Druckausgabe besteht in jedem Fall aus den Zeilen
"Headline", "Comment", "Title",
sowie aus allen Zeilen der Arbeitstabelle mit Ausnahme von
Basic-Zeilen. Zeilennummer und Zeilensetting werden nicht
gedruckt.
Print from / to row bestimmt den Bereich der gedruckten Zeilen und wird vom System selbst auf Stand gehalten. Natürlich kann der Bereich auch selbst festgelegt werden.
Ähnlich Print from / to column: Der Bereich
der gedruckten Spalten wird vom System gesetzt, kann aber
jederzeit verändert werden. Abgesehen davon gibt es im
Spaltensetting der Arbeitstabelle die Möglichkeit, einzelne
Spalten vom Ausdruck auszuschließen.
Sie werden die Gesamtlänge der Druckzeile im Auge behalten
müssen. Zur Breite jeder Spalte addiert sich ein Zeichen für
die Rasterlinie bzw. das Leerzeichen zwischen den Spalten, und
eines für den äußeren Rand. Sofern Ihr Drucker es erlaubt,
kann die Druckzeile bis zu 160 Zeichen lang werden.
Im Feld Column grid line kann ein einzelnes Zeichen in ASCII-Code angegeben werden, das zwischen den Spalten gedruckt wird. Wird nichts angegeben, druckt das System ein Leerzeichen zwischen den Spalten.
Im Feld Row grid line kann analog ein Zeichen festgelegt werden, das über die ganze Zeilenlänge zwischen den Tabellenzeilen gedruckt wird. Wird das Leerzeichen (ASCII 32) angegeben, so wird eine leere Zwischenzeile gedruckt. Enthält das Feld keine Angabe, so wird überhaupt keine Zwischenzeile gedruckt.
Im Feld Intersection kann ein weiteres Zeichen angegeben werden, das an den Schnittstellen von Spalten- und Zeilenraster gedruckt wird..
Perform / Reset headline erlauben die Eingabe eines ASCII-Codes (oder einer Code-Sequenz), der vor und nach der Tabellenüberschrift an den Drucker gesendet wird. Bei einer Sequenz aus mehreren Codes müssen die Codes mit SHIFT RETURN in getrennte Unterzeilen geschrieben werden. Fehlt die Angabe, ist das Feld ohne Wirkung.
Im Feld Perform / Reset col. titles kann in ähnlicher Weise eine Steuersequenz zur Gestaltung der Spaltenüberschriften angegeben werden.
Das Feld Define print codes kann benutzt
werden, um einzelnen Zeichen einen bestimmten ASCII-Code
zuzuweisen. Hier können z.B. die für den jeweiligen Drucker
gültigen Codes für die Sonderzeichen éäöüßÄÖÜ
eingetragen werden. Das geschützte Leerzeichen SHIFT SPACE wird
systemintern als ASCII-Code 224 verarbeitet, möglicherweise muß
es durch das übliche ASCII 160 ersetzt werden.
Die Eingabeform erfordert, daß zuerst das betreffende Zeichen
angegeben wird, gefolgt (mit oder ohne Leerzeichen dazwischen)
vom numerischen Code. Danach kann bei Bedarf ein Kommentar
angefügt werden, der vom System ignoriert wird. Unbedingt muß
für jedes definierte Zeichen mit SHIFT RETURN
eine eigene Zeile verwendet werden. Fehlerhafte Syntax wird vom
Programm ohne Fehlermeldung ignoriert.
Wenn ASCII set IBM ausgewählt ist, werden die Kleinbuchstaben a-z in ASCII-Code 97-122 umgewandelt, und die Großbuchstaben A-Z in 65-90, während im CBM-Set die Kleinbuchstaben durch die Codes 65-90 und die Großbuchstaben durch 193-218 dargestellt werden.
Die Felder BASIC open printer und BASIC close printer müssen Basic-Anweisungen zum Öffnen und Schließen des Druckfiles enthalten. Die Anweisungen können für verschiedene Drucker jeweils etwas anders aussehen. Möglicherweise muß mehr als ein File geöffnet werden, oder es sind vorab ein paar Kommandos an den Drucker zu senden. Falls mehr als ein File geöffnet wird, ist zu beachten, daß die Druckausgabe der Arbeitstabelle über die Filenummer gesendet wird, die zuletzt geöffnet oder benutzt wurde. Die Ausgabe selbst kann von Basic nicht kontrolliert werden, da es sich um eine Kopie der Bildschirmausgabe handelt. Aber es gibt ohnehin eine Reihe von Möglichkeiten. Beispielsweise kann auch die Export-Data-Option genutzt werden, um Daten an einen Drucker auszugeben, so wie umgekehrt auch die Druckausgabe der Arbeitstabelle in ein Diskfile umgeleitet werden kann, indem man statt eines Druckers ein File auf Diskette öffnet.
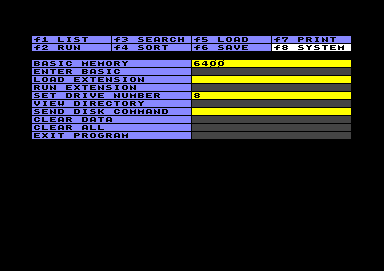 Systemoptionen
SystemoptionenUnter diesem Menüpunkt finden sich eine Reihe unterschiedlicher Optionen. Manche werden einfach durch ein RETURN im linken Feld ausgeführt, andere benötigen eine Eingabe im rechten Feld.
In den Systemoptionen ist die Möglichkeit vorgesehen, kleine Extra-Programme mit zusätzlichen Features zu laden und auszuführen. Der Vorteil dieser Konzeption ist, daß das Hauptprogramm nicht durch eine Vielzahl möglicherweise nie benutzter Funktionen vergrößert wird. Der Nachteil ist, daß diese Extra-Programme immer erst geladen werden müssen, falls man sie braucht.
Ist so eine Erweiterung einmal geladen, steht sie im System so lange zur Verfügung, bis an ihrer Stelle eine andere Erweiterung geladen wird. Auch wenn Sie ein neues Datatool-File laden oder ein "Clear all" ausführen, bleibt die Erweiterung bestehen.
Wie Sie gleich sehen werden, haben die Erweiterungsprogramme eigene Settingfelder, in denen Sie verschiedene Einstellungen vornehmen können. Diese Einstellungen werden zusammen mit dem Datatool-File gespeichert. Sie brauchen also, wenn Sie eine Erweiterung mit dem gleichen File öfter verwenden, die Settings nicht immer neu eingeben. Das ändert aber nichts daran, daß Sie die Erweiterung auf Systemebene erstmal laden müssen, ehe Sie auf die im File gespeicherten Settings zugreifen können.
Die Erweiterung wird als "pivot.extn" im System-Menü geladen. Der Sinn der Sache ist es, bestehende, listenartige Datensammlungen in Kreuz- bzw. Pivot-Tabellen umzuwandeln. Einführungen und Anwendungsbeispiele zu dieser Technik lassen sich im Internet finden.
Hier nun folgendes Beispiel: Nehmen wir an, Sie haben eine Liste mit Ihrer ganzen Commodore-Hardware angelegt, die etwa so aussieht:
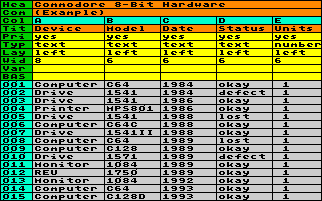 Sie haben also Spalten, in denen Inhalte mit
einer begrenzten Anzahl von Möglichkeiten stehen (z.B. A
Geräteart, B Modell, C Anschaffungsjahr und D Status)
und eine numerische Spalte (E Anzahl der Einheiten). Sie haben also Spalten, in denen Inhalte mit
einer begrenzten Anzahl von Möglichkeiten stehen (z.B. A
Geräteart, B Modell, C Anschaffungsjahr und D Status)
und eine numerische Spalte (E Anzahl der Einheiten).Nachdem die Liste schon sehr lang ist, verlieren Sie langsam schon den Überblick und möchten wissen, wie viele Einheiten von welchem Modell intakt, defekt oder verloren sind. Das Problem könnte man vielleicht auch mit Basic lösen, doch eleganter wäre es, aus der bestehenden Tabelle eine neue zu generieren, die genau die Informationen enthält, auf die es Ihnen ankommt. |
 Die geladene
Erweiterung wird aufgerufen, hier nehmen Sie nun einige
Einstellungen vor. Danach sollten Sie das File mit den
Originaldaten sichern, so bleiben Ihnen nämlich diese
Einstellungen auf Dauer erhalten, falls Sie die
Pivot-Tabelle später aufgrund von Änderungen neu
erstellen möchten. Die geladene
Erweiterung wird aufgerufen, hier nehmen Sie nun einige
Einstellungen vor. Danach sollten Sie das File mit den
Originaldaten sichern, so bleiben Ihnen nämlich diese
Einstellungen auf Dauer erhalten, falls Sie die
Pivot-Tabelle später aufgrund von Änderungen neu
erstellen möchten.Die Erweiterung zielt darauf ab, ein neues Tabellenfile mit ausgesuchten Daten zu erstellen. (Das Printersetting der Originaldatei wird dabei übrigens automatisch übernommen.) Headline und Comment stellen die Überschriften für dieses neue Tabellenfile dar. Als nächstes müssen Sie angeben, aus welchen Spalten Daten übernommen werden sollen. Title x bezieht sich auf die horizontale Achse: aus den Inhalten der angegebenen Spalte werden Spalten in der neuen Tabelle generiert. In unserem Beispiel wählen wir Spalte D, die den Status enthält. Title y bezieht sich auf die vertikale Achse: die Inhalte der angegebenen Spalte bilden die Zeilen in der neuen Tabelle. Wir wählen Spalte B, sie enthält das Modell. Und die Spalte, die unter Value eingegeben wird, stellt die Daten dar, die in Abhängigkeit von x und y arrangiert werden sollen. Bei uns ist das Spalte E, mit der Anzahl der Units. Mit den Einstellungen Layout und Width können Sie die Gestaltung der neuen Tabelle bestimmen. Wir wählen Width 6, um das Ergebnis in einem Screenshot unterzubringen. Natürlich kann das Layout der neuen Tabelle später jederzeit geändert werden. Unter dem anzugebenden Filename wird das neue Tabellenfile gespeichert. Sie bekommen es also nicht gleich zu sehen, wenn Sie Extract&save aufrufen, sondern müssen das neue File erst laden. Falls Sie aus bestimmten Rohdaten immer wieder Pivot-Tabellen generieren, spart es Ihnen Tipparbeit, wenn Sie den Filenamen der Pivot-Tabelle auch gleich im Menü f5 der Originaltabelle als Filenamen eingetragen haben. |
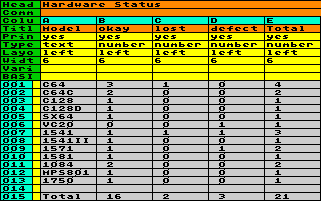 In der neuen
Pivot-Tabelle finden Sie nun ganz links die Spalte vor,
die Sie als Title y definiert haben. Gleichlautende
Einträge (z.B. 4 mal C64) wurden zu einer Zeile
zusammengefaßt. Die Reihung entspricht dem Vorkommen in
der Originaltabelle, daher wurden im Beispiel die Daten
zuvor noch rasch nach Spalte A sortiert, um sie nach
Gattung vorzugruppieren. Die nächsten Spalten enthalten
die verschiedenen Einträge von Title x als
Spaltenüberschriften, auch hier sind die
Mehrfachnennungen zusammengefaßt. Die numerischen Daten
in diesen Spalten geben die Werte wieder, die Sie als
Value definiert haben, zugeordnet zu den Kombinationen
von x und y. Abschließend steht eine automatisch
generierte Spalte Total, in der die Zeilensummen gebildet
werden. Analog werden in der letzten Zeile die
Spaltensummen generiert. (Falls Sie die Pivot-Tabelle nun
weiter in Basic bearbeiten, müssen Sie gegebenfalls
aufpassen, daß die Zeile mit den Spaltensummen nicht
versehentlich mitverarbeitet wird - Sie können z.B. mit
einer Basic-Zeile ein Flag davor setzen.) In der neuen
Pivot-Tabelle finden Sie nun ganz links die Spalte vor,
die Sie als Title y definiert haben. Gleichlautende
Einträge (z.B. 4 mal C64) wurden zu einer Zeile
zusammengefaßt. Die Reihung entspricht dem Vorkommen in
der Originaltabelle, daher wurden im Beispiel die Daten
zuvor noch rasch nach Spalte A sortiert, um sie nach
Gattung vorzugruppieren. Die nächsten Spalten enthalten
die verschiedenen Einträge von Title x als
Spaltenüberschriften, auch hier sind die
Mehrfachnennungen zusammengefaßt. Die numerischen Daten
in diesen Spalten geben die Werte wieder, die Sie als
Value definiert haben, zugeordnet zu den Kombinationen
von x und y. Abschließend steht eine automatisch
generierte Spalte Total, in der die Zeilensummen gebildet
werden. Analog werden in der letzten Zeile die
Spaltensummen generiert. (Falls Sie die Pivot-Tabelle nun
weiter in Basic bearbeiten, müssen Sie gegebenfalls
aufpassen, daß die Zeile mit den Spaltensummen nicht
versehentlich mitverarbeitet wird - Sie können z.B. mit
einer Basic-Zeile ein Flag davor setzen.)Nun haben Sie also auf einen Blick, welche Modelle Ihrer Sammlung mit welchem Status zur Verfügung stehen. Ebenso könnten Sie auch die Originaldaten nach Modell und Anschaffungsjahr gruppieren, und falls Sie eine Spalte für den Kaufpreis vorgesehen haben, könnten Sie mittels Pivot-Tabelle auch sehr leicht feststellen, wieviel Geld Sie in welchem Jahr für welche Sachen ausgegeben haben. Mit der Erweiterung für Säulendiagramme können Sie Pivot-Tabellen auch grafisch darstellen. Das macht die Sache noch übersichtlicher. |
Das Beispiel illustriert die Möglichkeiten. Nun noch einige Hinweise zu Bedingungen und Einschränkungen dieses kleinen Erweiterungsprogramms:
Der Name der Erweiterung ist "plot.extn". Sie ermöglicht es, numerische Daten in einem Punktdiagramm darzustellen. Voraussetzung ist, daß die Daten nach Spalten angeordnet sind, sodaß also zusammengehörige Datensätze in Zeilen vorliegen. Angezeigt werden ausschließlich Zeilen der Arbeitstabelle, die vom Typ "Data" sind, nicht also "Result" Zeilen.
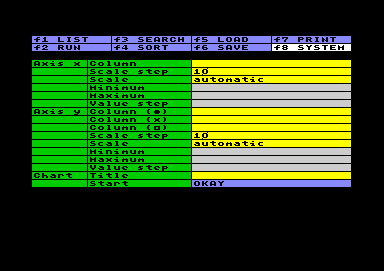 Wenn Sie einen raschen grafischen Überblick
über den Verlauf von Daten haben wollen, ist das Setting
denkbar einfach: Geben Sie nur unter Column
den Buchstaben der Spalten an, in denen die Daten liegen,
und belassen Sie die Einstellung Scale
auf automatic. Für die y-Achse können
Sie bis zu drei verschiedene Spalten gleichzeitig
anzeigen lassen, repräsentiert durch ein jeweils anderes
Symbol (Punkt, Kreuz oder Rechteck). Das Programm
ermittelt die weiteren Settingwerte automatisch und
produziert eine Grafik mit einer Größe von 20*20
Bildschirmzeichen. Werden in jeder Achse nicht mindestens
zwei unterschiedliche Werte vorgefunden, gibt es die
Fehlermeldung "Missing data". Leere Datenfelder
der Arbeitstabelle werden nicht als Wert Null
interpretiert, sondern als nicht vorhanden. Wenn Sie einen raschen grafischen Überblick
über den Verlauf von Daten haben wollen, ist das Setting
denkbar einfach: Geben Sie nur unter Column
den Buchstaben der Spalten an, in denen die Daten liegen,
und belassen Sie die Einstellung Scale
auf automatic. Für die y-Achse können
Sie bis zu drei verschiedene Spalten gleichzeitig
anzeigen lassen, repräsentiert durch ein jeweils anderes
Symbol (Punkt, Kreuz oder Rechteck). Das Programm
ermittelt die weiteren Settingwerte automatisch und
produziert eine Grafik mit einer Größe von 20*20
Bildschirmzeichen. Werden in jeder Achse nicht mindestens
zwei unterschiedliche Werte vorgefunden, gibt es die
Fehlermeldung "Missing data". Leere Datenfelder
der Arbeitstabelle werden nicht als Wert Null
interpretiert, sondern als nicht vorhanden.Meistens werden Sie mit dem automatischen Entwurf nicht recht einverstanden sein. Sie können nun, getrennt für jede Achse, auf Einstellung manual umschalten und die Parameter selbst festlegen. Im einzelnen bewirken sie folgendes:
Die Relation von Value step und Scale step bestimmt den Maßstab der Grafik. Wenn Sie Scale step vergrößern oder Value step verkleinern, wird die Grafik größer. Ausgehend von der Größe der automatisch generierten Grafik können Sie die Grafik in y-Richtung verdoppeln und in x-Richtung etwa verdreifachen. Wenn Sie die Größe beibehalten möchten, muß bei Änderungen des einen Parameters der andere im (etwa) gleichen Verhältnis geändert werden. Falls Sie Daten (speziell in der x-Achse) in regelmäßigen Intervallen vorliegen haben, müssen Sie die Auflösung an die Intervalle anpassen, um eine optisch saubere Ausgabe zu erzielen. Die Auflösung ergibt sich aus der Division Value step / Scale step. Diese muß in einem geraden Verhältnis zum vorgegebenen Intervall liegen, also entweder ein ganzzahliges Vielfaches oder ein Bruch durch eine ganze Zahl. Sie werden vielleicht eine Weile herumexperimentieren müssen, bis Sie zu einer zufriedenstellenden Darstellung kommen. Dabei kann kaum was schiefgehen. Es gibt keine Fehlermeldung, wenn die Grafik die Maximalgröße sprengt, da auch die Möglichkeit gegeben sein soll, einen kleinen Ausschnitt der Grafik heranzuzoomen und den Rest außer Beachtung zu lassen. |
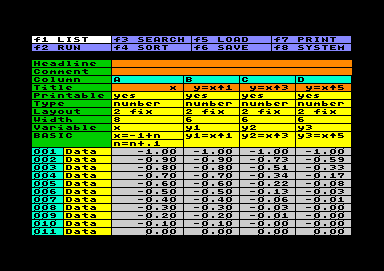 Im Beispiel links wurden verschiedene Potenzen von x berechnet, wobei x in Schritten von 0.1 im Bereich zwischen -1 und 1 fortschreitet. Die mit Basic generierte Arbeitstabelle hat im Beispiel 21 Datenzeilen in 4 Spalten: eine für den x-Wert und drei weitere für die Potenzen x^1, x^3 und x^5 in der y-Achse. Im Plot Setting wurden einfach die Spalten A (Axis x) und B-D (Axis y) eingetragen. Da das Beispiel für einen einfachen Plot-Test angelegt ist, zeigt die automatische Erstellung gleich ein recht brauchbares Bild. |
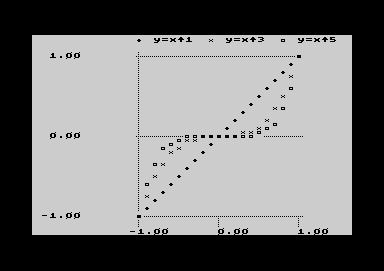
Der Ausgabebereich der Grafik ist 80 Zeichen breit und 50 Zeichen
hoch, also in jeder Richtung doppelt so groß wie der Bildschirm.
Sie können das Sichtfenster mit den CRSR-Tasten
verschieben. HOME bringt Sie in die
Ausgangsposition, mit PFEIL-LINKS oder RETURN gelangen Sie wieder zum Setting
zurück.Die Auflösung in der x-Achse ist eine Zeichenbreite, in
der y-Richtung eine halbe Zeichenhöhe. Wenn sich y-Werte
verschiedener Spalten unterhalb des Auflösungsvermögens
schneiden, überlagern sich ihre Symbole zu einem ausgefüllten
Rechteck.
Die Beschriftung der Achsenwerte erfolgt in den gewählten Abständen von "Scale step". Der Skalenwert ergibt sich rein rechnerisch aus Minimum und Value step. Das Programm übernimmt dabei der Beschriftung Layout und Breite der Spalten aus der Arbeitstabelle. Falls die Beschriftung optisch danebenliegt, können Sie das durch Breite und Zahlenformatierung korrigieren. Die verfügbare Breite ist in der x-Achse durch den gewählten Skale step begrenzt, in der y-Achse ist sie fix 12 Zeichen.
Sofern die Spalten in der Arbeitstabelle betitelt sind, fügt das Programm den Spaltentitel zusammen mit dem zugehörigen Symbol oben als Legende zur y-Achse ein. Analog wird die x-Achse mit dem zugehörigen Spaltentitel beschriftet (im Screenshot nicht mehr sichtbar). Der im Erweiterungssetting angegebene Chart-Title steht über der Grafik (hier ebenfalls nicht mehr zu sehen).
Eine Möglichkeit Grafiken auszudrucken existiert nicht, und ist auch nicht vorgesehen. Allerdings gibt es eine Erweiterung, die es ermöglicht, Grafiken als GeoPaint-File zu exportieren, um sie weiter zu bearbeiten und zu drucken.
Der Name der Erweiterung ist "bar.extn".
Damit können Daten als verschiedenfärbige Säulen
representiert werden. Die x-Achse, auf der die Säulen
aufgetragen werden, kann sowohl aus Text wie aus Zahlen
bestehen. 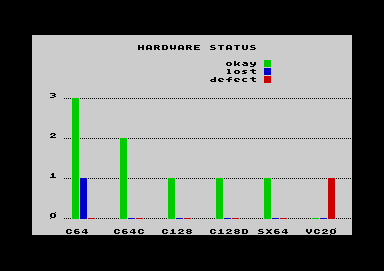 Diese
Art der Grafik ist vor allem für kleinere Datenmengen
geeignet, die nach verschiedenen Gesichtspunkten
vergleichbar gemacht werden sollen. Während mit Plot
eher Rohdaten gezeigt werden, können mit Säulengrafiken
sehr gut "raffinierte", bereits verarbeitet
Daten präsentiert werden. Anders als bei der
Plot-Erweiterung werden Zeilen vom Typ "Result"
ebenso angezeigt wie "Data". (Sie können also
auch Spaltensummen oder Durchschnitte anzeigen lassen,
dies aber auch durch die Auswahl eines bestimmten
Zeilenabschnittes verhindern.) Diese
Art der Grafik ist vor allem für kleinere Datenmengen
geeignet, die nach verschiedenen Gesichtspunkten
vergleichbar gemacht werden sollen. Während mit Plot
eher Rohdaten gezeigt werden, können mit Säulengrafiken
sehr gut "raffinierte", bereits verarbeitet
Daten präsentiert werden. Anders als bei der
Plot-Erweiterung werden Zeilen vom Typ "Result"
ebenso angezeigt wie "Data". (Sie können also
auch Spaltensummen oder Durchschnitte anzeigen lassen,
dies aber auch durch die Auswahl eines bestimmten
Zeilenabschnittes verhindern.)Die Erweiterung ist
einfach in der Anwendung und eine ideale Ergänzung zur Pivot-Erweiterung, da sich jede
Pivot-Tabelle umgehend grafisch darstellen läßt. Im
Screenshot rechts ist das oben gebrachte Beispiel mit der
Hardwareliste zu sehen. Lassen Sie sich nicht durch die
Achsen verwirren: die in der Pivot-Tabelle erstellte
y-Achse wird in der Grafik zur x-Achse. |
Im Setting haben Sie unter Column die Spalten anzugeben, aus denen die Daten entnommen werden. Die Spalte in der x-Achse kann, wie gesagt, numerisch oder alphanumerisch sein. Da der Inhalt nur als eine Abfolge von Fällen behandelt wird, gibt es keinen Maximal- oder Minimalwert, stattdessen können Sie in den Felder From row / to row den Zeilenbereich auswählen, der in der Grafik erfaßt werden soll. Scale step in der x-Achse bestimmt, in welchen Abständen die Einträge erfolgen. Gezählt wird in Bildschirmzeichen. Möglich ist eine Angabe zwischen 2 und 30. Der erforderliche Abstand richtet sich nach der Anzahl der Säulen und nach der Breite der Beschriftung. Ist der Scale step kleiner als die Säulenanzahl, wird die Vorgabe ignoriert. 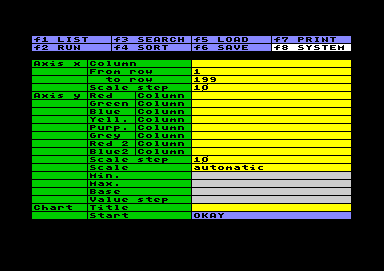 In der y-Achse
können Sie unter Column bis zu 8
Spalten eintragen. Diese Werte werden dann als
verschiedenfärbige Säulen dargestellt. Der Scale
step in der y-Achse bestimmt, in welchen
Abständen eine Skalenlinie eingezogen wird. Auch hier
ist ein Wert zwischen 2 und 30 möglich. Im Wahlfeld Scale
können Sie zwischen automatic und manual wählen. Bei
Einstellung automatic brauchen Sie sich
um die weiteren Settings nicht zu kümmern. Die Automatik
erstellt eine Säulengrafik mit einer Höhe von 10
Bildschirmzeichen. Die Einstellung von Scale step sollte
in dem Fall 5, 10 oder 20 sein (drei, zwei oder nur eine
Skalenlinie). Bei Einstellung manual
können Sie die weiteren Parameter der Grafik selbst
festlegen. Es ist immer empfehlenswert, den ersten Lauf
mit automatic durchzuführen und erst dann an den
Settings zu feilen. Min. und Max.
legen den Wertebereich in der y-Achse fest. Im
Unterschied zum Plot-Diagramm ist es nicht egal, wenn ein
Wert diese Grenzen überschreitet, denn es gibt eine
Fehlermeldung - und zwar einen Basic-Error (da zur
Berechnung Routinen des C64-Betriebssystems herangezogen
werden). Base legt fest, von welchem
Ausgangswert die Säulen gezeichnet werden. In den
meisten Fällen wird Base identisch mit dem Minimum sein,
in dem Fall wachsen die Säulen nach oben. Sie können
jedoch auch einen höheren Base-Wert festlegen, sodaß
die Säulen von dieser Ausgangslinie nach unten wachsen.
Der Base-Wert muß sich nicht mit der Skaleneinteilung
der y-Achse treffen, Sie können also auch irgendeinen
"krummen" Wert festlegen, um z.B. Abweichungen
vom Durchschnitt oder irgendwelchen anderen
Erwartungswerten darzustellen. Value step
bestimmt, analog zum Scale step, die Wertdifferenz
zwischen den Skalenlinien. Da müßen Sie nun aufpassen,
da die Relation von Scale step (in Zeichen) und Value
step (in der y-Einheit) den Maßstab und die Größe der
Grafik bestimmt. Und anders als bei der Plot-Grafik
können Sie keinen bestimmten Ausschnitt heranzoomen, da
bei einer Überschreitung der Maximalgröße von 30
Bildschirmzeichen eine Fehlermeldung erfolgt. Der
kleinstmögliche Wert für Value step ist (Max.-Min.) *
Scale step / 30. Sie müssen hier also etwas vorsichtig
hantieren und bei Veränderungen die Relation von Value
step und Scale step im Auge behalten. In der y-Achse
können Sie unter Column bis zu 8
Spalten eintragen. Diese Werte werden dann als
verschiedenfärbige Säulen dargestellt. Der Scale
step in der y-Achse bestimmt, in welchen
Abständen eine Skalenlinie eingezogen wird. Auch hier
ist ein Wert zwischen 2 und 30 möglich. Im Wahlfeld Scale
können Sie zwischen automatic und manual wählen. Bei
Einstellung automatic brauchen Sie sich
um die weiteren Settings nicht zu kümmern. Die Automatik
erstellt eine Säulengrafik mit einer Höhe von 10
Bildschirmzeichen. Die Einstellung von Scale step sollte
in dem Fall 5, 10 oder 20 sein (drei, zwei oder nur eine
Skalenlinie). Bei Einstellung manual
können Sie die weiteren Parameter der Grafik selbst
festlegen. Es ist immer empfehlenswert, den ersten Lauf
mit automatic durchzuführen und erst dann an den
Settings zu feilen. Min. und Max.
legen den Wertebereich in der y-Achse fest. Im
Unterschied zum Plot-Diagramm ist es nicht egal, wenn ein
Wert diese Grenzen überschreitet, denn es gibt eine
Fehlermeldung - und zwar einen Basic-Error (da zur
Berechnung Routinen des C64-Betriebssystems herangezogen
werden). Base legt fest, von welchem
Ausgangswert die Säulen gezeichnet werden. In den
meisten Fällen wird Base identisch mit dem Minimum sein,
in dem Fall wachsen die Säulen nach oben. Sie können
jedoch auch einen höheren Base-Wert festlegen, sodaß
die Säulen von dieser Ausgangslinie nach unten wachsen.
Der Base-Wert muß sich nicht mit der Skaleneinteilung
der y-Achse treffen, Sie können also auch irgendeinen
"krummen" Wert festlegen, um z.B. Abweichungen
vom Durchschnitt oder irgendwelchen anderen
Erwartungswerten darzustellen. Value step
bestimmt, analog zum Scale step, die Wertdifferenz
zwischen den Skalenlinien. Da müßen Sie nun aufpassen,
da die Relation von Scale step (in Zeichen) und Value
step (in der y-Einheit) den Maßstab und die Größe der
Grafik bestimmt. Und anders als bei der Plot-Grafik
können Sie keinen bestimmten Ausschnitt heranzoomen, da
bei einer Überschreitung der Maximalgröße von 30
Bildschirmzeichen eine Fehlermeldung erfolgt. Der
kleinstmögliche Wert für Value step ist (Max.-Min.) *
Scale step / 30. Sie müssen hier also etwas vorsichtig
hantieren und bei Veränderungen die Relation von Value
step und Scale step im Auge behalten. |
Im Beispiel, auf dem der Screenshot
rechts beruht, werden die verschiedenen Möglichkeiten
untersucht, mit dem C64 Zufallszahlen zu erzeugen. rnd(1) liefert eine ab dem
Einschaltzustand reproduzierbare Zufallsfolge, rnd(0) immer eine neue, nicht
reproduzierbare Zufallszahl. 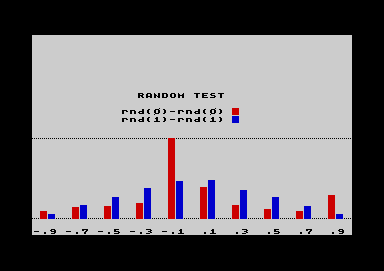 Untersucht wird nun die Differenz zweier
Zufallszahlen, die auf die eine oder andere Art erzeugt
wurden. Im Detail ist die Vorgangsweise hier irrelevant,
nur ganz kurz: Im Menü f2 Basic-Presetting wurde für
jede der beiden Zufallsmethoden ein dimensioniertes Feld
eingerichtet. Die Ergebnisse der Subtraktion zweier
Zufallszahlen wurden in 10 Wertegruppen geordnet, und
für jeden "Treffer" in einer dieser
Wertegruppen wurde die entsprechende Feldvariable
erhöht, und dies in einem Loop über einige tausend mal.
Es handelt sich also um eine Zählung von Häufigkeiten.
Im Spalten-Basic wurden dann bloß noch die Werte aus den
dimensionierten Variablen in Tabellenfelder übertragen.
Die Arbeitstabelle hat in dem Fall also 10 Zeilen und
drei Spalten. Die Spalte der x-Achse enthält das Zentrum
des Wertebereichs (+/- 0.1), die beiden y-Spalten die
Trefferhäufigkeiten. Untersucht wird nun die Differenz zweier
Zufallszahlen, die auf die eine oder andere Art erzeugt
wurden. Im Detail ist die Vorgangsweise hier irrelevant,
nur ganz kurz: Im Menü f2 Basic-Presetting wurde für
jede der beiden Zufallsmethoden ein dimensioniertes Feld
eingerichtet. Die Ergebnisse der Subtraktion zweier
Zufallszahlen wurden in 10 Wertegruppen geordnet, und
für jeden "Treffer" in einer dieser
Wertegruppen wurde die entsprechende Feldvariable
erhöht, und dies in einem Loop über einige tausend mal.
Es handelt sich also um eine Zählung von Häufigkeiten.
Im Spalten-Basic wurden dann bloß noch die Werte aus den
dimensionierten Variablen in Tabellenfelder übertragen.
Die Arbeitstabelle hat in dem Fall also 10 Zeilen und
drei Spalten. Die Spalte der x-Achse enthält das Zentrum
des Wertebereichs (+/- 0.1), die beiden y-Spalten die
Trefferhäufigkeiten.Das Ergebnis zeigt, daß rnd(1)-rnd(1) eine schöne Normalverteilung liefert, rnd(0)-rnd(0) hingegen Spitzen aufweist, die mit Zufall nichts zu tun haben können. (rnd (0) berechnet Zufallszahlen aus einem Zeitgeber und ist höchstens dann zufällig, wenn zwischen den einzelnen Abfragen eine zufällige Zeitspanne liegt, was bei einem laufenden Basic-Programm eben nicht der Fall ist.) |
Die Grafikausgabe arbeitet so wie bei der Plot-Grafik: Der Ausgabebereich ist 80 Zeichen breit und 50 Zeichen hoch, also in jeder Richtung doppelt so groß wie der Bildschirm. Sie können das Sichtfenster mit den CRSR-Tasten verschieben. HOME bringt Sie in die Ausgangsposition, mit PFEIL-LINKS oder RETURN gelangen Sie wieder zum Setting zurück. Die maximale Größe des Säulendiagramms ist 30 Zeichen vertikal und 66 Zeichen horizontal. Die Auflösung in y-Richtung ist ein Pixel, beträgt also Value step / Scale step / 8 in Einheiten der y-Skala.
Die x-Achse wird mit den Einträgen der angegebenen Spalte beschriftet. Die Beschriftung beginnt 1 Zeichen links von der ersten Säule. Durch Variation von Layout und Breite der Spalte in der Arbeitstabelle können Sie die Beschriftung beeinflussen, wobei die Breite nicht größer als der in x-Richtung eingestellte Scale step sein sollte. Die Reihenfolge, in der die Säulen dargestellt werden, hängt von der Reihenfolge der Spalten in der Arbeitstabelle ab, nicht von der Reihenfolge der Farben im Setting.
Die Markierungslinien in y-Richtung sind rein rechnerisch auf Grundlage von Value step beschriftet, ausgehend vom Minimum. Über Value step und Scale Step können Sie also viele Zwischenmarkierungen (jede zweite Bildschirmzeile) einfügen, oder ganz auf sie verzichten, indem Sie einen Scale step wählen, der höher ist als die Grafik. Wenn der Base-Wert vom Raster abweicht, wird er extra beschriftet. Das Layout der y-Beschriftung wird ebenfalls durch die Arbeitstabelle festgelegt, die maximale Breite ist 12. Über der Grafik steht die Legende der y-Werte mit den zugehörigen Farben. Dazu werden die Spaltentitel der Arbeitstabelle herangezogen. Ganz oben steht der Titel der Grafik, sofern er im Setting angegeben wurde.
Eine Möglichkeit Grafiken auszudrucken existiert nicht, und ist auch nicht vorgesehen. Allerdings gibt es eine Erweiterung, die es ermöglicht, Grafiken als GeoPaint-File zu exportieren, um sie weiter zu bearbeiten und zu drucken.
Die zuletzt beschriebenen Erweiterungen zum Erstellen von Grafiken bringen das Resultat nur auf den Bildschirm. Durch die Vielzahl verschiedener Drucker ist es nicht so einfach, sie auf Papier zu bringen. GeoPaint ist ein sehr verbreitetes Anwenderprogramm und bietet eine unerreichbare Fülle an Druckertreibern. Daher wurde der relativ kürzeste Umweg gewählt, die Grafiken als GeoPaint-File zu exportieren.
Der Name der Erweiterung ist "chart2geos.extn".
Nachdem Sie ein Punkt- oder Säulendiagramm fertiggestellt haben,
laden und starten Sie die Erweiterung im System-Menü. Wichtig
dabei ist, daß Sie den Feldpuffer nicht benutzen, denn in diesem
ist die Grafik zwischengespeichert. Sie dürfen z.B. nicht im
Directory mit RETURN einen Filenamen in
den Puffer holen, sonst ist die Grafik weg!
Das erzeugte File wird im Geos-VLIR-Format exportiert, was einige Implikationen hat. Das DOS der Commodorelaufwerke kann dieses Format nicht richtig verwalten. Bei einem v(alidate)-Befehl an das Laufwerk werden die Grafikdaten des Geos-Files gelöscht, obwohl der Filename im Disk-Inhaltsverzeichnis erhalten bleibt. Umgekehrt löscht der s(cratch)-Befehl zwar den Filenamen aus dem Disk-Inhaltsverzeichnis, nicht jedoch die Datenblöcke der Grafikdaten. Bei der Angabe von Filename haben Sie die Möglichkeit, ein bestehendes File mit der Einleitung "@:" zu überschreiben. Dabei wird der Filename im Inhaltsverzeichnis gelöscht und neu beschrieben, jedoch werden die belegten Blocks des alten Files nicht freigegeben, sodaß Sie beim wiederholten Überschreiben eines Files vor der Tatsache stehen, daß der verfügbare Diskspeicher immer weniger wird. In diesem Fall sollten Sie die Disk unter Geos aufräumen, damit der nicht benutzte Diskspeicher ohne Gefahr für aktuelle Geos-Files freigegeben wird. Am besten speichern Sie das GeoPaint-File gleich auf einer eigenen Geos-Disk, damit es zu keinen Verwirrungen kommt.
 Mit der Einstellung Color image
können Sie wählen, ob Sie die Grafik färbig oder
schwarzweiß exportieren möchten. Bei Punktdiagrammen
ist die Einstellung völlig egal, bei Säulendiagrammen
können die Farben durch Muster ersetzt werden, wenn Sie
über keine Möglichkeit zum Farbausdruck verfügen. Mit der Einstellung Color image
können Sie wählen, ob Sie die Grafik färbig oder
schwarzweiß exportieren möchten. Bei Punktdiagrammen
ist die Einstellung völlig egal, bei Säulendiagrammen
können die Farben durch Muster ersetzt werden, wenn Sie
über keine Möglichkeit zum Farbausdruck verfügen. |
Die Erweiterung gibt einen "Incompatible format"-Error wenn sich im Puffer keine Grafik befindet (z.B. weil nach dem Erzeugen der Grafik der Feldpuffer benutzt wurde). Wird versucht, ein bestehendes File gleichen Namens ohne "@:" zu überschreiben, gibt es die Floppy-Fehlermeldung "File exists". Wenn bei einer fast vollen Disk während des Speichern ein Überlauf eintritt, gibt es einen "Illegal track or sector"-Drive-Error, der in dem Fall nur besagt, daß keine weitere Speichermöglichkeit auf Disk vorhanden ist. Theoretisch sollte die Erweiterung mit allen Laufwerkstypen funktionieren, getestet wurde sie aber nur mit einer 1541 und einer FD2000 im 1581-Modus.
Bei diesem Erweiterungsprogramm handelt es sich um eine modifizierte Version eines Savers aus dem C64 Image Processing System GoDot. Vielen Dank an Arndt Dettke, der mir den kommentierten Quellcode zur Verfügung gestellt hat!
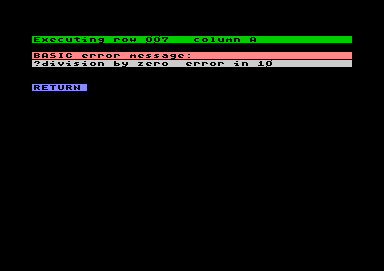 Fehlermeldungen
FehlermeldungenFehlermeldungen können unterschiedliche Herkunft haben: sie stammen entweder vom Basic-Interpreter, vom Drive, oder vom System selbst.
Systemwarnungen:
Systemfehlermeldungen:
Wenn mit einer Spaltenvariablen Rechenoperationen
durchgeführt werden, wird das Ergebnis angezeigt, auch wenn es
Null ist. Manchmal kann es optisch vorteilhafter sein, wenn
anstelle der Null eine völlig leere Zelle gezeigt wird. Das kann
erreicht werden, indem eine nicht benutzte Spalte als numerischer
Typ gesetzt und mit einer Variablen versehen wird, z.B. die leere
Spalte Z mit Variable z. Diese
Variable kann nun jeder anderen Spaltenvariable zugewiesen
werden, um eine leere Zelle zu erzwingen, z.B.: if a=0 then a=z.
Mathematisch ist kein Unterschied zwischen einem leeren Datenfeld
und Null, und für Berechnungen in Basic spielt es auch keine
Rolle. Für Erweiterungsprogramme kann es allerdings eine
Unterschied machen: so interpretieren die Chart-Extensions leere
Datenfelder nicht als Null, sondern als nicht vorhanden!
Beim Eingeben von Listen mir immer wiederkehrenden Titeln kann es viel Arbeit sparen, Abkürzungen zu verwenden, die vom Spalten-Basic vervollständigt werden, z.B.:
if a$="x" then a$="Titel
X"
if a$="y" then a$="Titel Y"
if a$="z" then a$="Titel Z"
Die Umwandlung von numerischen Daten am Bildschirm verlangsamt die Bewegung des Bildschirms spürbar, besonders wenn mehrere numerische Spalten mit geringer Breite zu sehen sind. Wenn der Großteil der Arbeit im Eingeben und Edieren der Daten besteht, und weniger im Rechnen, kann es Abhilfe schaffen, wenn die numerischen Daten als Text eingegeben und erst bei Berechnungen in Basic mittels der VAL() Funktion in numerische Werte umgewandelt werden. Das beschleunigt die Darstellung am Bildschirm, aber es verlangsamt die Ausführung von Basic, und ein weiterer Nachteil besteht darin, daß die Grafik-Erweiterungen an reinen Text-Daten nicht verwendet werden können.
In Sonderfällen, z.B. bei Näherungsberechnungen in dokumentierten Schritten, wäre es nützlich, wenn die zunächst unbekannte Anzahl der bearbeiteten Zeilen von Basic aus während des Laufs variiert werden könnte. Das ist durch Manipulation von Systemregistern zu erreichen. Folgende Register (dezimal) können gesetzt oder ausgelesen werden:
| 167 (Low-Byte) | 168 (High-Byte) | aktuelle (laufende) Zeilennummer, kann ggf. nur erhöht werden |
| 679 (Low-Byte) | 682 (High-Byte) | Vorgabe für Anzahl der Durchläufe |
| 680 (Low-Byte) | 683 (High-Byte) | Vorgabe für letzte inkludierte Zeilennummer im Lauf |
| 681 (Low-Byte) | 684 (High-Byte) | Nummer des aktuellen Durchlaufs |
Die systeminterne Erfassung der Zeilennummer ist immer um 9 höher als die angezeigte Zeilennummer in der Arbeitstabelle, da für das System die Settingzeilen mitzählen. peek(167)+256*peek(168)-9 würde z.B. die aktuelle Zeilennummer von 1 bis 999 liefern.
Das C64-Basic und das DOS der Commodore-Floppys erlaubt das Anlegen und Lesen von Daten auf Disk. Vorgesehen ist dafür der Typ des sequentiellen Files mit der Kennzeichnung SEQ im Directory. Ein paar Regeln sollten im Auge behalten werden:
Die Basic-Anweisungen print#, get#, und input#, sind bequem zum Austauschen von Daten, haben aber auch ihre Finessen. Hier ein kurzer Überblick:
| Strings | Zahlen | |
| Senden | print#2,x$ sendet den Inhalt der Variable x$ und ein Carriage Return (CR = ASCII 13) hinterher, das beim Empfangen das Ende der Variable signalisiert. (Mit einem Semikolon kann das CR unterdrückt werden: print#2,x$; ) Soll die Variable x$ mit input# empfangen werden, darf sie kein Komma enthalten und auch nicht leer sein, also zuvor auf Leerstring prüfen, z.B.: if x$="" then x$=chr$(0) | print#2,x sendet
einen Zahlenwert nicht in einem bestimmten numerischen
Format, sondern als Ziffernstring. Um einzelne Bytes (0-255) zu senden, kann der Wert in ASCII-Code umgewandelt und als einzelnes Zeichen gesendet werden: print#2,chr$(x); |
| In der print# Anweisung können auch mehrere Variable, durch Semikolon oder Komma getrennt, hintereinander geschrieben werden. Der Effekt ist der, daß die Variablen ohne CR oder sonstigem Trennzeichen gesendet werden und sich beim Empfangen nicht mehr zuordnen lassen. Nur wenn man weiß, daß es sich bei den Variablen um einzelne Bytes handelt, kann das sinnvoll sein. Ansonsten sollte für jede Variable ein eigenes print# Statement verwendet werden. | ||
| Empfangen | get#2,x$ empfängt ein einzelnes Zeichen. Eine Ausnahme ist, wenn das empfangene Byte Null ist. Dann enthält x$ nicht ein Zeichen mit dem Code Null, sondern hat eine Länge von Null. Wenn Sie die ASC-Funktion ausführen wollen, müssen Sie das in Form von x=asc(x$+chr$(0)) tun, um eine Fehlermeldung zu vermeiden. | get#2,x erwartet eine einzelne Ziffer im ASCII-Code. Da es eine Fehlermeldung gibt, sobald das empfangene Zeichen vom Ziffernformat abweicht, wird diese Anweisung eigentlich nie verwendet. Um ein einzelnes Byte zu empfangen, verwendet man get#2,x$ und die ASC-Funktion. |
| input#2,x$ sammelt Zeichen in der Variable, bis entweder ein Komma (ASCII 44) oder ein CR (ASCII 13) das Ende der Variable signalisiert. Der empfangene String darf weder leer noch länger als 80 Zeichen sein. | input#2,x liest einen Ziffernstring bis zum Trennzeichen ein und wandelt ihn in eine numerische Variable um. Weicht ein Zeichen vom Ziffernformat ab, gibt es eine Fehlermeldung. | |
| Bei get# und input# können auch mehrere Variablen, getrennt mit Komma, hintereinander angegeben werden. Das ist kein Gegenstück zur ähnlich aussehenden Option beim print# , denn die aufgereihten Variablen werden genau in der Weise empfangen wie es bei einer Reihe von Einzelanweisungen der Fall wäre. | ||
| Franz Kottira | kottira@webnet.at | Frankie´s C64 Seite |
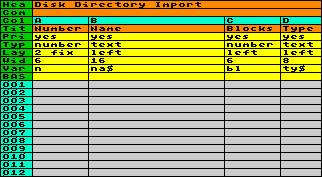 Zunächst
müssen Sie die Arbeitstabelle vorbereiten. Sie sehen
eine Spalte für eine laufende Nummer vor, und zwar
Spalte A, mit der zugeordneten Variable n, Typ numerisch, Spaltenweite 6,
mit 2 festen Nachkommastellen. Im ganzzahligen Teil soll
die laufende Disknummer, im Nachkommateil die laufende
Filenummer gespeichert werden. Ferner sehen Sie Spalte B
für den Disk- bzw. Filenamen vor und weisen ihr die
Variable na$ zu. Spalte C ist
für die Filelänge vorgesehen, numerisch mit Variable bl. Und Spalte D soll den Filetyp
mit der zugeordneten Variable ty$ enthalten.
Zunächst
müssen Sie die Arbeitstabelle vorbereiten. Sie sehen
eine Spalte für eine laufende Nummer vor, und zwar
Spalte A, mit der zugeordneten Variable n, Typ numerisch, Spaltenweite 6,
mit 2 festen Nachkommastellen. Im ganzzahligen Teil soll
die laufende Disknummer, im Nachkommateil die laufende
Filenummer gespeichert werden. Ferner sehen Sie Spalte B
für den Disk- bzw. Filenamen vor und weisen ihr die
Variable na$ zu. Spalte C ist
für die Filelänge vorgesehen, numerisch mit Variable bl. Und Spalte D soll den Filetyp
mit der zugeordneten Variable ty$ enthalten.